Replicate's Cog project is a watershed moment for AI
Contents
I’ve argued that Pattern Synthesis (“AI”, LLMs, ML, etc) will be a defining paradigm of the next technology cycle. Patterns are central to everything we as humans do, and a mechanism that accelerates their creation could have impact on work, culture and communications on the same order as the microprocessor itself.
If my assertion here is true, one would expect to see improving developer tools for this technology: abstractions that make it easy to grab Pattern Synthesizers and apply them to whatever problem space you may have.
Indeed, you can pay the dominant AI companies for access to their APIs, but this is the most superficial participation in the Pattern Synthesis revolution. You do not fully control the technology that your business relies upon, and you therefore find yourself at the whims of a platform vendor who may change pricing, policies, model behaviors, or other factors out from beneath you.
A future where Pattern Synthesis is a dominant technical paradigm is one where the models themselves are malleable, first-class development targets, ready for experimentation and weekend tinkering.
That’s where the Cog project comes in.
Interlude: the basics of DX in Pattern Synthesis
The Developer Experience of Pattern Synthesis, as most currently understand it, involves making requests to an API.
This is a well-worn abstraction, used today for everything from accepting payments to orchestration of cloud infrastructure. You create a payload of instructions, transmit it to an endpoint, and then a response gives your application what it needs to proceed.
Through convenient API abstractions, it’s easy to begin building a product with Pattern Synthesis components. But you will be fully bound by the model configuration of someone else. If their model can do what you need, great.
But in the long term, deep business value will come from owning the core technology that creates results for your customers. Reselling a widget anyone else can buy off the shelf doesn’t leave you with much of a moat. Instead, the successful companies of the coming cycle will develop and improve their own models.
Components of the Pattern Synthesis value chain
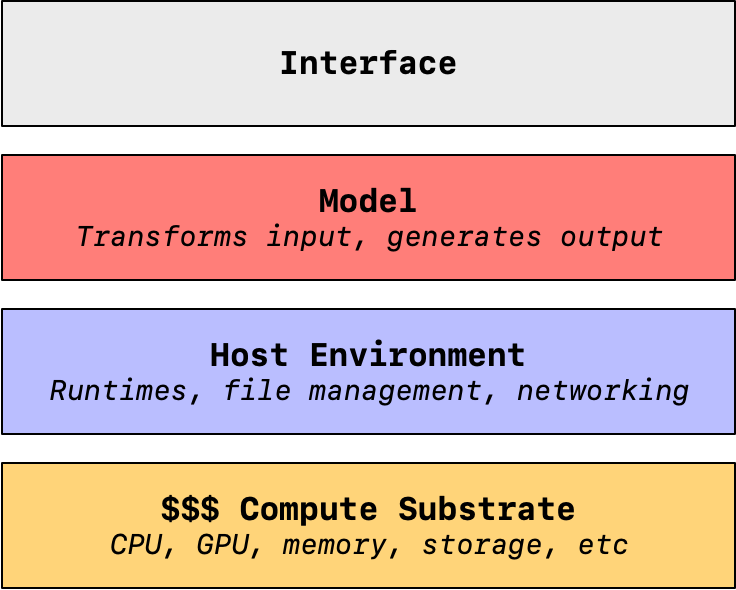
In order to provide the fruits of a Pattern Synthesis Engine to your customers, you’ll be interacting with these components:
- Compute substrate: Information is physical. If you want to transform data, you’re going to need physical hardware somewhere that does the job. This a bunch of silicon that stores the data and does massive amounts of parallelized computation. This stuff can be expensive, with Nvidia’s A100 GPU costing $10k just to get started.
- Host environment: Next, you’re going to need an operating system that can facilitate the interaction between your Pattern Synthesis model and the underlying compute substrate. A host environment does all of the boring, behind-the-scenes stuff that makes a modern computer run, including management of files and networking, along with hosting runtimes that leverage the hardware to accomplish work.
- Model: Finally we arrive at the Pattern Synthesizer itself. A model takes inputs and uses a stored pile of associations it has been “trained” with to transform that input into a given pattern. Models are diverse in their applications, able to transform sounds into text, text into images, classify image contents, and plenty more. This is where the magic happens, but as we can see, there are significant dependencies before you can even get started interacting with the model.
- Interface: Finally, an interface connects to these lower layers in order to provide inputs to the model and report its synthesized output. This starts as an API, but this is usually wrapped in some sort of GUI, like a webpage.
This is the status quo, and it’s not unique to “AI” work, either. You can swap the “model” with “application” and find this architecture describes the bulk of how the existing web works.
As a result, existing approaches to web architecture have lessons to offer the developer experience for those building Pattern Synthesis models.
Containerization
In computing, one constant bugbear is coupling. Practitioners loathe tightly coupled systems, because such coupling can slow down future progress. If one half of a tightly coupled system becomes obsolete, the other half is weighed down until it can be cut free.
A common coupling pattern in web development exists between the application and its host environment. This can become expensive, as every time the application needs to be hosted anew, the environment must then be set up from scratch to support its various dependencies. Runtimes and package managers are common culprits here, but the dependency details can be endless and surprising.
This limits portability, acting as a brake on scaling.
The solution to this problem is containerization. With containers, an entire host environment can be snapshotted and captured into fully portable files. Docker, and its Docker Engine runtime, is among the most well-known tools for the job.
Docker Engine provides a further abstraction between between the host environment and its underlying compute resources, allowing containers that run on it to be flexible and independent of specific hardware and operating systems.
There’s a lot of devil in these details. There’s no magic here, just hard work to support this flexibility.
But when it works, it allows complex systems to be hoisted into operation across a multitude of operating systems on a fully-automated basis. Get Docker Engine running on your machine, issue a few terminal commands, and you’ve got a new application running wherever you want it.
With Cog, Replicate said: “cool, let’s do that with ML models.”
Replicate’s innovation
Replicate provides hosting for myriad machine learning models. Pay them money, you can have any model in their ecosystem, or one you trained yourself, available through the metered faucet of their API.
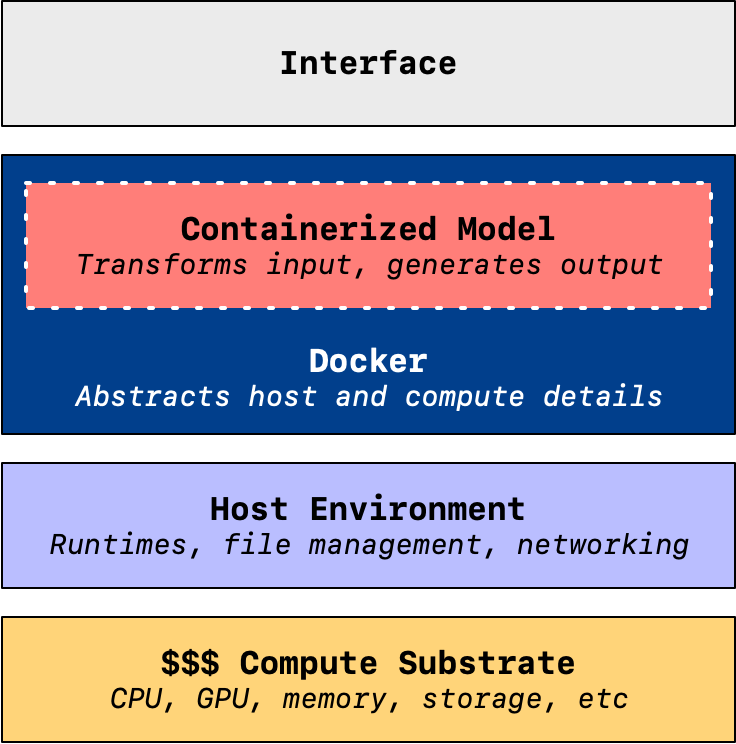
To support this business model, Replicate interposes Docker into the existing value chain. Rather than figure out the specifics of how to make your ML model work in a particular hosting arrangement, you package it into a container using Cog:
No more CUDA hell. Cog knows which CUDA/cuDNN/PyTorch/Tensorflow/Python combos are compatible and will set it all up correctly for you.
Define the inputs and outputs for your model with standard Python. Then, Cog generates an OpenAPI schema and validates the inputs and outputs with Pydantic.
Thus, through, containerization, the arcane knowledge of matching models with the appropriate dependencies for a given hardware setup can be scaled on an infinitely automated basis.
The model is then fully portable, making it easy to host with Replicate.
But not just with Replicate. Over the weekend I got Ubuntu installed on my game PC, laden as it is with a high-end—if consumer-grade—GPU, the RTX 4090. Once I figured out how to get Docker Engine installed and running, I installed Cog and then it was trivial to load models from Replicate’s directory and start churning out results.
There was nothing to debug. Compared to other forays I’ve made into locally-hosted models, where setup was often error-prone and complex, this was so easy.
The only delay came in downloading multi-gigabyte model dependencies when they were missing from my machine. I could try out dozens of different models without any friction at all. As promised, if I wanted to host the model as a local service, I just started it up like any other Docker container, a JSON API instantly at the ready.
All of this through one-liner terminal commands. Incredible.
The confluence of Pattern Synthesis and open source
I view this as a watershed moment in the new cycle.
By making it so easy to package and exchange models, and giving away the underlying strategy as open source, Replicate has lowered the barriers to entry for tinkerers and explorers in this space. The history of open source and experimentation is clear.
When the costs become low enough to fuck around with a new technology, this shifts the adoption economics of that technology. Replicate has opened the door for the next stage of developer adoption within the paradigm of Pattern Synthesis. What was once the exclusive domain of researchers and specialists can now shift into a more general—if still quite technical—audience. The incentives for participation in this ecosystem are huge—it’s a growth opportunity in the new cycle—and through Cog, it’s now so much easier to play around.
More than that, the fundamental portability of models that Cog enables changes the approaches we can take as developers. I can see this leading to a future where it’s more common to host your models locally, or with greater isolation, enabling new categories of “AI” product with more stringent and transparent privacy guarantees for their customers.
There remain obstacles. The costs of training certain categories of model can be astronomical. LLMs, for example, require millions of dollars to capitalize. Still, as the underlying encapsulation of the model becomes more amenable to sharing and collaboration, I will be curious to see how cooperative approaches from previous technology cycles evolve to meet the moment.
Keep an eye on this space. It’s going to get interesting and complicated from here.

